A guide to GROQ
Aug 5, 2023
GROQ (Graph Relational Object Queries) is a query language that was created by Sanity to query CMS data. It’s a flexible query language and the use of projections makes it a powerful tool to construct complex and efficient data queries.
GROQ vs. GraphQLAt their heart they are both query languages, but where GraphQL returns data in an inflexible shape, GROQ allows you to project your data into the shape you request. I dig deeper in to GROQ vs GraphQL in another post

GROQ is sanity’s query language of choice.
You can use GraphQL but that requires a deploy of the endpoints so it’s not as flexible when you’re changing data schemas.Under the hood, GROQ is just querying JSON documents - which is how Sanity stores the data. If you inspect the document in the CMS you can see this. A query just returns all documents that pass the specified filter e.g. _type == "article":
1{
2 "_id": "drafts.9c8433d6-257a-4c29-934d-6992db16f08e",
3 "_type": "article",
4 "type": "default",
5 "hidden": false,
6 "language": "en",
7 "title": "A guide to GROQ",
8 "slug": {
9 "_type": "slug",
10 "current": "guide-to-groq"
11 },
12 "tags": [
13 {
14 "_type": "reference",
15 "_key": "47c275b5d73b",
16 "_ref": "615f7edc-d52e-48f8-8cb6-0168ee0190e5"
17 },
18 {
19 "_type": "reference",
20 "_key": "122cb9c75b50",
21 "_ref": "dd686ca1-0e63-4c4f-895a-ae3fc37be122"
22 },
23 {
24 "_type": "reference",
25 "_key": "39f4b73c9d8c",
26 "_ref": "97a06789-24e3-4c2e-b915-921f18ed287a"
27 }
28 ]
29}The basics of queriesQueries are normally executed either using a Sanity Client from the web app, or, by using the “Vision” tool in the CMS to run live queries. The basic syntax is quite simple.
Source - What you want to query on…Filter - The part which narrows down the data to the items you wantProjection - The part which describes the fields you wantSort - How you want to sort the dataSlice - What subset of the data you want.Anatomy at a glance1*[ _type == "article" ] {
2 title,
3 body
4 publishedDate
5} | order(publishedDate desc)[0..10]SourceThe source is the part before the filter (the bit in the []) represented by an asterisks (*)
*[]. In 99.9% of cases this will always be the case. There may be odd cases where you want to reuse data in a sub query, e.g. dataSource[] but that’s rare and I’m getting ahead of myself, and you probably don’t need it yet!FiltersA filter is everything between the [] .
1const query1 = `*[]` // No query, i.e. all documents
2
3const query2 = `*[_type == "article"]` // All articles
4
5const query3 = `*[_type == "article" && someAttibute==true]` // With someAttribte
6
7const res = await sanityClient.fetch(query3, params); // Run the queryNote the double equals in the equality. This is not JS equalityFilters can be based on equality or scalar eg. value==anotherValue or value >= 100Filters can use functions dateTime(publishedDate) > dateTime('2023-08-11T05:42:00Z')filters can be joined with a double ampersand &&, or be used as either with a double pipe ||Filters can be grouped with brackets (x == 1 && y == 2)Filters can also take dynamic params by using a dollar in front of the parameter key slug == $querySlug. More on this later…ProjectionsA projection returns the data structure you want. By default a query only returns the object _id.
To specify other properties of an object we need to specifically ask for them by using {} and adding the names to the projection:
1*[_type=="article"] {
2 title,
3 publishedDate,
4 body,
5 tags
6}Note: the fields should be exactly as they are on the schema definition, should not be enclosed in "", and should be followed by a ,.Note: There is a special syntax to retrieve all fields for an object .... This should be used sparingly as it will almost always bring back fields that are unused, resulting in a bigger payload. Save the data! ☮️1*[_type=="article"] {
2 ...
3}You can also remap field names using a field in quotes "" :
1*[_type=="article"] {
2 "newTitle": title, // remap title to newTitle,
3 "extraTitle": "HARDCODED_VALUE"
4}Sorts & slicesSortingSorting is done with the order() keyword. It takes arguments and sorts the results by it.
1*[_type == "movie"] | order(score) {
2 title,
3 score,
4}Note the | before the order(). Sanity handles queries as a flow from left to right. The sections of the flows are joined with a pipe. We can join multiple projections together. The data is passed from left to right, but it is up to you to add it to the next projection. Once dropped it cannot be retrieved. The query below will only have a score field.
1*[] {
2 score,
3 title,
4 director
5} | order(score desc) | {
6 score
7}You can order by multiple values just by using multiple comma separated values order(score desc, title asc, director, desc).
Slicing is done with a [] after the section and is either [0..10] or [0...9] exclusive .. or inclusive ...
1*[] {
2 score,
3 title,
4 director
5} | order(score desc) [0..10]If we want the top 10 we need to sort it by the score, then slice the result.
If you want just the single item just use[0] at the end of the query. The top document!1*[] {
2 score,
3 title,
4 director
5} | order(score desc)[0]We can also filter the results with [] and add a criteria, in this case we only want items with a score greater than 5
1*[] {
2 score,
3 title,
4 director
5} [score > 5] | order(score desc) Special syntax and helpersFunctionsThere are multiple functions available to use with GROQ. The following is just a small subset, but are probably the ones that I find most useful on a daily basis.
count()You can also use special functions to derive a new values. We can count the number of a field with count(). This is useful for things like, getting the number of tags an article has.
1*[_type == "article"] {
2 "howManyTags": count(tags)
3}coalesce()We can combine to use one value over another where it’s set using coalesce(). This will use the first "truthy" value as the value, and fall back to a default if specified. This is useful when the value of a field is optional and you need to provide a fallback. I've used this a lot to set default language to en.
1*[_type == "article"] {
2 "language": coalesce(__i18nlang, "en"),
3}select()We can set a value based on a specific criteria, such as assigning movie ratings as works depending on the score using select(). This is useful to set distinct values for a field, such as specific words for score ranges.
1*[_type == "movie"] {
2 "rating": select(
3 score > 9 => "Great",
4 score > 5 => "OK",
5 "Rubbish!"
6 )
7}references()This is going to get confusing for a minute. Let me explain. A reference is a 2 way relationship. On one side, we have a document which points to another. This document stores any references it has on its own document. For example, an article might point to a tag.
On the other side we have a document that IS being referenced by another document. For example, the TAG is referenced by the article. In the second case, the tag doesn't have a list of all documents that are referencing it. It is for the second case why we have the references() function.
The function takes an _id and looks for all documents that have a _ref which matches the _id.
_id in a sub query we need to get it from the parent. To access a property from a parent you use a caret (^) to point up a level. So to access a parent’s _id, you would use ^._id and for a grandparent ^.^._id and so on.It’s best to demo it for references in a nested query. In the following we have a query which brings back all tags. Within each tag, we also make a query for all article which are using the current tag in their references by using ^._id to access the parent tag's _id.
1*[_type=="tag"]{
2 _id,
3 name,
4 "articles": *[_type=="article" && references(^._id)] {
5 title
6 }
7}ReferencesHow can you get the data from a reference in a document? You can “follow” the referenced field.
Going back to my JSON example in the intro, you may have noticed that the tags are all references.
1{
2 "tags": [
3 {
4 "_type": "reference",
5 "_key": "47c275b5d73b",
6 "_ref": "615f7edc-d52e-48f8-8cb6-0168ee0190e5"
7 },
8 {
9 "_type": "reference",
10 "_key": "122cb9c75b50",
11 "_ref": "dd686ca1-0e63-4c4f-895a-ae3fc37be122"
12 },
13 {
14 "_type": "reference",
15 "_key": "39f4b73c9d8c",
16 "_ref": "97a06789-24e3-4c2e-b915-921f18ed287a"
17 }
18 ]
19}To get a referenced document's fields rather than just the _ref we can use an arrow syntax ->. This tells GROQ to follow the reference and we can then project its data as per other queries.
[] to specify that it’s an array of values to follow: []-> Tags is a good example of this:1*[_type == "article"] {
2 tags // returns and array of [{ "_ref": "hash" }]
3}This would be changed tp:
1*[_type == "article"] {
2 tags[]-> { // Add []->
3 slug, // And project the fields required
4 name
5 },
6}Now we get the content of the referenced fields:
1{
2 "tags:": [
3 {
4 "slug": {
5 "current": "typescript",
6 "_type": "slug"
7 },
8 "name": "TypeScript"
9 },
10 {
11 "slug": {
12 "current": "fundamentals",
13 "_type": "slug"
14 },
15 "name": "Fundamentals"
16 }
17 ]
18}For content such as portable text, there can be references that need to be followed. This can be done with a check to see if the type is a reference and conditionally following it. This would be useful where you have content blocks like images, maps, and other document based content that you need to retrieve to display it.
1{
2 'body': body[]{
3 // A reference - Follow it and return it
4 _type == 'reference' => @->,
5 // On this object, just return it
6 _type != 'reference' => @,
7 }
8}Portable text is just an array of content objects with a _type onMultiple queriesTo make multiple queries we can pass an object with the queries on:
1{
2 "tags": *[_type=="tag"] { ... },
3 "articles": *[_type=="article"] { ... },
4 "people": *[_type=="people"] { ... },
5} // returns an object with the keys tags, articles, peopleThese can also be piped, although in this case you could just wrap the “article” query in a count() for the same result but this is just a demo!
1{
2 "articles": *[_type=="article"] { ... },
3} | {
4 "article_count": count(articles),
5}You can also access the values from the object with a .KEY
1{
2 "articles": *[_type=="article"] { ... },
3} | {
4 "article_count": count(articles),
5}.article_count // Returns the value 99 and not { "article_count": 99 }Alternate sourcesRemember how I sad that 99.9% or queries would be on all data so the source is almost always *, well there can also be other sources. If there is a case where you are repeating a query multiple times with minor variations they you can create a data source that will encompass the repeated queries and filter on that. Let me demo.
Imagine we want to get all the english and french articles for each tag. We query all documents for type=="tag". Then we create a new key for "en_articles" and create a query on all documents for articles which the language is en AND which reference the parent id using ^.id . We then do the same for the french articles, and so on.
1*[_type == "tag"] {
2 "en_articles" : *[_type=="article" && language == "en" && references(^._id)] { ... },
3 "fr_articles" : *[_type=="article" && language == "fr" && references(^._id)] { ... },
4 "es_articles" : *[_type=="article" && language == "es" && references(^._id)] { ... },
5}Not only is this multiple almost identical database queries, but it’s also more code to maintain if we need to update the filter. Let’s refactor the query to make a generic query, then filter on that. First, we query for all articles, we then pipe that data from left to right and in the second projection we query the "all_articles" by replacing the * with all_articles . Since this is already just articles that references the tag, it will filter on the subset.
1*[_type == "tag"] {
2 "all_articles" : *[_type=="article" && references(^._id)] { ... },
3 } | {
4 "en_articles" : all_articles[language == "en"] { ... },
5 "fr_articles" : all_articles[language == "fr"] { ... },
6 "es_articles" : all_articles[language == "es"] { ... },
7}This still has a query for every tag, so we can go a step further. We make a query for all articles, pipe this to another projection where we do a query for all tags and project the existing all_articles for each tag as tag_articles. We then filter again on that for each individual language. Finally we append .tags so that the resulting data is not an object with a tags key, but just an array of tags.
1{
2 "all_articles": *[_type=="article"]
3} | {
4 "tags": *[_type == "tag"] {
5 "tag_articles" : all_articles[references(^._id)] { ... }
6 } | {
7 "en_articles" : tag_articles[language == "en"] { ... },
8 "fr_articles" : tag_articles[language == "fr"] { ... },
9 "es_articles" : tag_articles[language == "es"] { ... },
10 }
11}.tagsParamsParams, as briefly mentioned earlier are written as a dollar sign followed by the name of the parameter $param (but not like a JS interpolated string ${ param }). They can be used to pass data into a query for things like matching a value such as a slug or query param.
1const data = sanityClient.fetch(query, {
2 querySlug: "sanity", // a value from a querystring perhaps
3 max: 10 // use as $max in the query
4})This will fetch the article with the slug the-groqqening and then return the single item so we can display it or whatever!
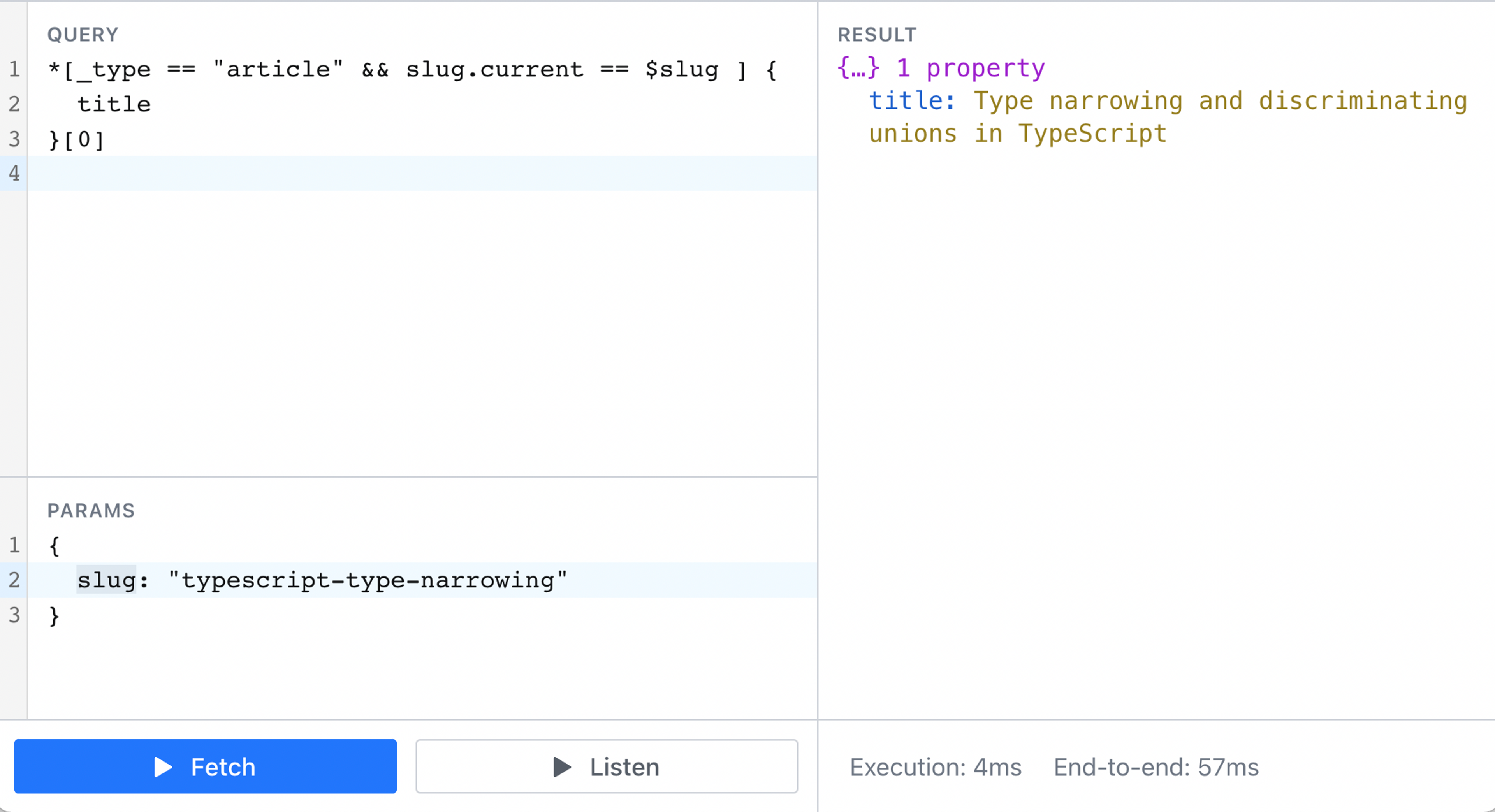
1const query = `*[_type == "article" && slug.current == $slug] { ... }[0]`;
2const params = { slug : "the-groqqening" };
3
4const data = sanityClient.fetch(query, params)You can pass pretty much any data into the params and use it as you need aid your query.
We can also do this in the vision editor:
As mentioned above, data flows from left to right. When the initial filter is run, all the data the resulting documents is available in the first projection:
1*[_type=="article"] {
2 title,
3 body,
4 tags
5}As soon as it is piped to the right in the flow, we need to “bring” the data we want along with us as once it’s piped anything not explicitly brought along will be left behind
1*[_type=="article"] {
2 title,
3 body,
4 tags,
5} | {
6 title,
7 category, // I didn't specify these in the initial projection
8 author // it will not be accessible
9}Next up, is derived fields ( Ones with "" around )cannot be accessed in the same projection. They need to be projected to be accessed. For example value will always return "less" because "num" will be undefined.
1*[_type=="article"] {
2 "num": count(tags[]),
3 "value": select( num > 2 => "many", "few")
4} | order(value)If we pipe this so that "num" is projected, then it will be accessible:
1*[_type=="article"] {
2 "num": count(tags[]),
3} | {
4 "value": select( num > 2 => "many", "few")
5} | order(value)One other gotcha, which is in the above query is that, while projected data is available to use in the next piped projection, if you don’t add it to the next projection, then it will be left behind. We can add it using the name num explicitly, or use the ... to bring across all previous values.
1*[_type=="article"] {
2 "num": count(tags[]),
3} | {
4 num,
5 "value": select( num > 2 => "many", "few")
6} | order(value)Joins and mathsField values can be manipulated with normal math functions such as addition, subtraction and multiplication.
1{
2 "title": "Hello" + "World!",
3 "maths": 10 + (10 / 5)
4}Portable textPortable text can also be manipulated with functions. For example, we can get the text content of the whole block with pt:text(body). We can then apply other functions to the resulting string to work out properties like reading time.
Setup your VSCode editor in the command line.
1export EDITOR='code -w'If you have a different IDE, then replace code -w with the relevant command to allow writing documents.Create a new document by running the command from your sanity project. You will need a sanity.cli.ts file configured so that you can access via the cli!
1npx sanity documents create --watch --replace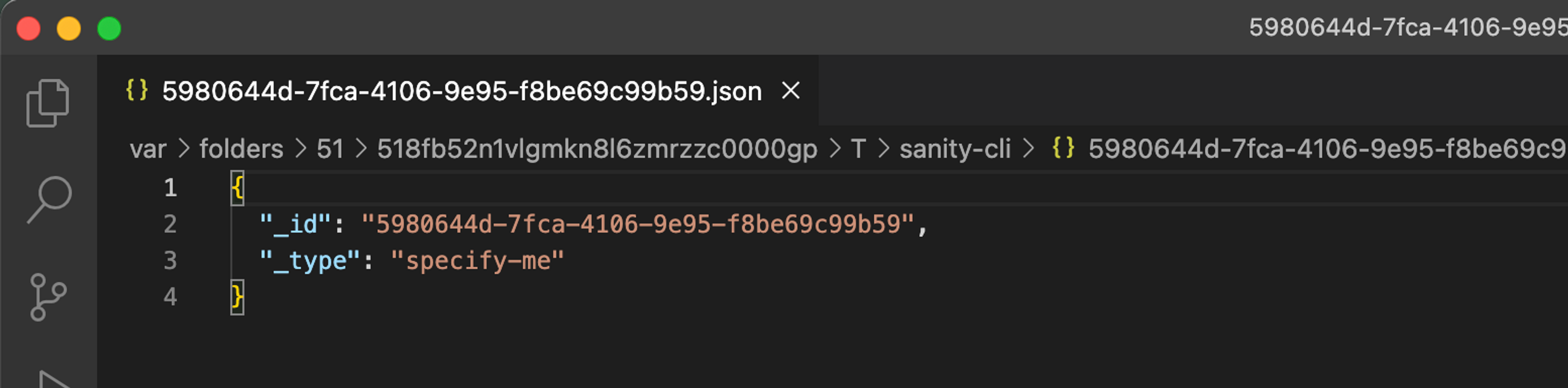
If you want to edit an existing document also add the --id DOC_ID flag and value
1npx sanity documents create --id myDocId --watch --replace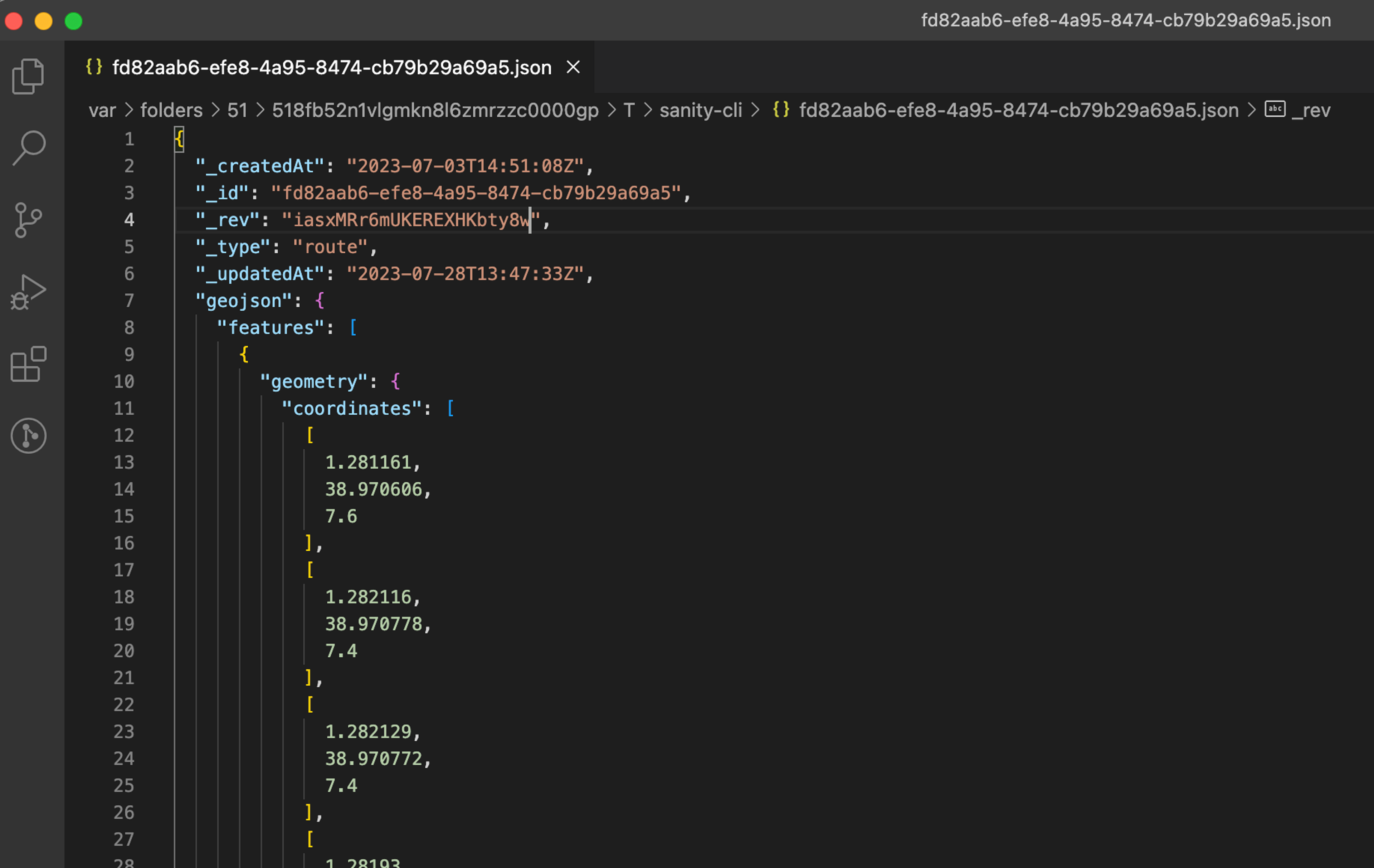
As you can see, GROQ is a powerful tool, that allows us to query for data in a way that gives us exactly what we want, rather than having to use JavaScript after the query to reformat data. It's a learning curve, but the basics are accessible, and the sanity Slack community is both friendly and knowledgable when you get stuck. To find out more about GROQ, or to have a play with some data and learn some skills check out the following links
Useful links5 neat tricks you can make the Sanity CLI doGROQ Query Cheat Sheet - Sort, Filter & Array ExamplesThe ultimate guide to GROQ - learn in under 1hrGROQ of ThronesGROQ Arcade - Query JSON in the browser